En värld av data
White Papers
Publicerat:
Kunskap och kännedom om ditt data är en förutsättning för att kunna ställa de relevanta frågorna och pressa informationen till max. Känner du till ursprunget av din data tillräckligt för att kunna säkerställa tillförlitlighet och kvalitet? Pooya Shahryari och Micael Starck diskuterar molntjänster, ETL, ELT och människans förhållande till data.
Vad är data? Information som beskriver vår värld omkring oss. Går det med andra ord att beskriva hela vår värld och kända universum med den data som finns tillgänglig i vår planets alla databaser? Det här är en mycket viktig aspekt när det kommer till data. Vad är det för data vi sparar på? Vad tycker vi människor är viktigt? Människor tenderar att värdera data som beskriver människor högst.
Efter det kommer data om händelser och objekt som finns omkring oss och påverkar oss. Vi kan dessutom inte formulera data om saker vi inte känner till. Men det är mycket data ändå. 2020 uppskattades mängden data online på internet till i runda slängar ett tiotal zettabyte (tiotal följt av 21 nollor). Och det växer lavinartat. Nu, eller i nära framtid, genererar ett par exabyte data dagligen (en etta följt av arton nollor). Just nu är det de stora drakarna (Google, Facebook, Microsoft och Amazon) som genererar mest data och lagrar i storleksordningen ett par tusen petabyte (tusen följt av femton nollor). Mängden data är ofattbar även om det matematiskt med siffror går att skriva ut mängden och studera den. Men för en vanlig dödlig är det svårt att ta in. Vad är det då som genererar all den här underbara datan?
Det är våra digitala aktiviteter som är den största källan; sociala nätverk, transaktioner, filmer/musik, ljud i kommunikation. Varje digital rörelse (klick) genererar en mängd avtryck och, liksom vågripplar, leder till att funktioner och processer aktiveras som i sin tur genererar mer data. Men även sensorer blir alltmer en källa till information som ska lagras och analyseras; allt från enkla analoga sensorer som mäter sin omgivning till smarta enheter som kan utföra mer komplexa uppgifter. Den senare kallas generellt Internet of Things, IoT, och kan vara små enheter som går att programmera och lära upp. Dessa stoppas girigt i alla möjliga mackapärer omkring oss; våra bilar, hus och deodoranter (!?) (https://www.metrikus.io/blog/10-weirdest-iot-enabled-devices-of-all-time ).
Men för att återgå till den ursprungliga frågan; går det med andra ord att beskriva hela vår värld och kända universum med den data som finns tillgänglig i vår planets alla databaser? Svaret är att det inte på långa vägar finns tillräckligt med data. Människan lagrar bara den data han/hon/hen finner intressant och det räcker inte till för att ge något svar på hela frågan. Vi kan heller inte samla in data om saker vi inte känner till. Inte förrän vi kommer på någon AI som kan förutse okända händelser (https://en.wikipedia.org/wiki/There_are_known_knowns ) vilket i sig är en spännande tanke.

Men om vi vänder på steken. Vad är det för frågor vi vill ha svar på med vår data? Med det kommer vi in på hur vi idag väljer att arbeta med data. Och här är det läge att beskriva en enkel process med hur inhämtning, bearbetning och analys av data ofta går till. Vi börjar med en problemformulering. Vad har vi för fråga/problem/utmaning som vi vill ha svar på? Kanske är det en enkel KPI som vi vill följa, exempelvis hur försäljningen av en viss produkt går. Efter att vi har en formulering följer en diskussion om vilken data som behövs för att kunna leverera svaret. Den kanske finns i en databas i egen regi, en fil i molnet, ett dataflöde från en sensor eller dylikt. Här kanske vi kommer på att vi inte har den data som behövs för att lösa uppgiften och måste backa och göra om problemformuleringen utifrån våra nya insikter. Inte alltid helt enkelt men det är viktigt att ha tålamod och vara noggrann i detta steg. När vi har vår data och kan extrahera den så ska vi bearbeta den. Och här börjar ett viktigt arbete som utförs till stor del av de vi kallar för dataingenjörer; extrahering, transformation och laddning, kort kallat för ETL. I det här arbetet ingår att hämta in data och koppla sig till alla de källor som behövs, bearbeta data för att få den i ordning och slutligen lägga den i diverse dataytor för att på så vis tillgängliggöra färdig data för analys.
Här tar våra datavetenskapsmän (direkt översatt från engelskan) över. Dessa skrider till verket med pannan i djupa veck, vrider och vänder på siffror och datapunkter för att söka svar på den ursprungliga frågeställningen. Kanske måste nya värden beräknas från de inhämtade. Efter detta följer presentation och en diskussion som skulle kunna vara slutet på arbetet. Men så är det inte. Arbetet går in på nästa varv. Nu ska vi justera den ursprungliga problemformuleringen med nya resultat och insikter färskt i minnet. Går det att jämföra försäljningen av produkten mot kundernas aktivitet i övrigt? Beror toppar och dalar på konkurrens av egna eller andras produkter? Går det att korrelera siffrorna till annan data? Och så är vi igång igen. Allt arbete kan beskrivas som en cykel där processerna itereras där ny data hämtas in och genererar nya insikter (och mer data 😊).
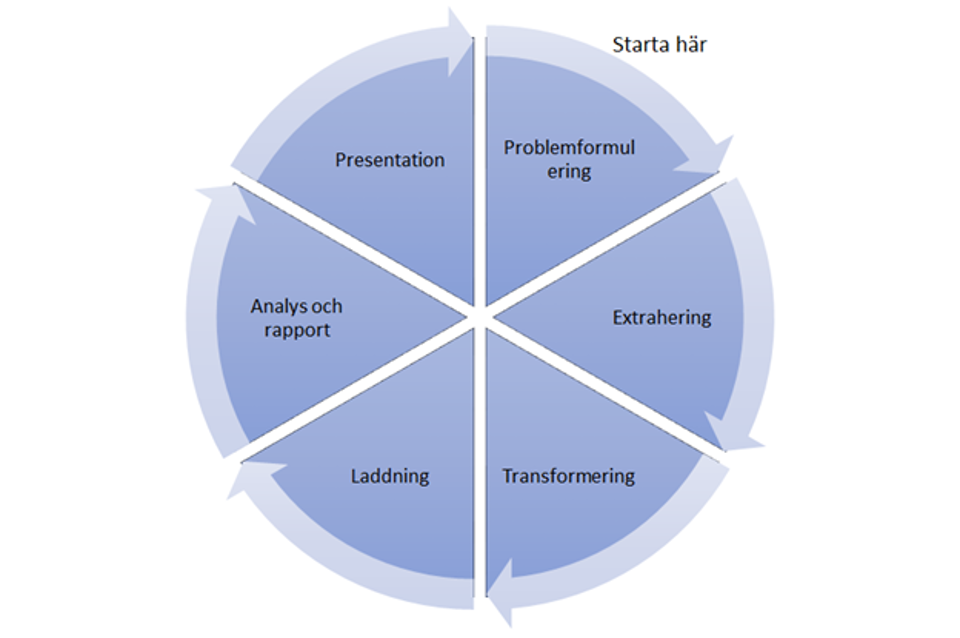
Det som är viktigt att ha i åtanke i ovan process är att kunskap och kännedom om sitt data är en förutsättning för att kunna ställa de relevanta frågorna och pressa informationen till max. Genom att förstå styrkor och nackdelar kan vi identifiera vad som är möjligt. Inhämtningen kräver förståelse av källan. Vi vill helst ha flera källor som beskriver samma information för att den ska vara tillförlitlig. Känner vi till ursprunget av vår data tillräckligt för att kunna säkerställa tillförlitlighet och kvalitet?
Även kvantitet är viktig i många fall. Källa ett kanske är mer gles än källa två som vi värderar högt. För att kunna nyttja källa två fullt ut kanske vi kan komplettera källa ett med ytterligare en källa, källa tre. När vi sedan är inne i bearbetningen behöver vi hitta gemensamma nämnare mellan datakällorna så att vi kan sy ihop/normalisera dom. Kan vi använda någon identifierare som förekommer i alla? Ska utgå från tid och rum (position)? Behövs ytterligare källa som kan översätta mellan de källor vi har? Det är genom denna bearbetning som vi lär känna vår data och dess förutsättningar att ge svar på våra frågor. Kanske hittar vi svar på frågor vi inte ställt (alltid spännande). Kanske inser vi att den data vi behöver inte finns och att vi måste börja generera den (gärna med deodoranten ovan).
För att fullt ut förstå processen kring ETL (extrahering, transformering/bearbetning och laddning) ska vi göra en lite djupare dykning i ämnet.
ETL står för extract, transform, load.
- EXTRAHERA data från dess ursprungliga källa
- TRANSFORMERA data genom att deduplicera dem, kombinera dem och säkerställa kvalitet
- LADDA data till destinationsdatabasen
Steg 1: EXTRACT
Innan data kan flyttas till en ny destination måste den först extraheras från dess källa – till exempel ett data warehouse eller data lake. I detta första steg av ETL-processen importeras strukturerad och ostrukturerad data och konsolideras till ett enda arkiv. Datavolymer kan extraheras från ett brett utbud av datakällor, inklusive:
- Befintliga databaser och äldre system
- Moln-, hybrid- och lokala miljöer
- Försäljnings- och marknadsföringsapplikationer
- Mobila enheter och appar
- CRM-system
- Datalagringsplattformar
- data warehouse
- Analysverktyg
Även om det kan göras manuellt med ett team av dataingenjörer, kan handkodad dataextraktion vara tidskrävande och risk för fel. ETL-verktyg automatiserar utvinningsprocessen och skapar ett mer effektivt och tillförlitligt arbetsflöde.
Steg 2: TRANSFORM
Under denna fas av ETL-processen kan regler och förordningar tillämpas som säkerställer datakvalitet och tillgänglighet. Man kan också tillämpa regler för att hjälpa företaget att uppfylla rapporteringskraven. Processen för datatransformation består av flera delprocesser:
- Rensning — inkonsekvenser och saknade värden i data åtgärdas.
- Standardisering – formateringsregler tillämpas på datamängden.
- Deduplicering — redundant data exkluderas eller kasseras.
- Verifiering — oanvändbar data tas bort och avvikelser flaggas.
- Sortering — data är organiserade efter typ.
- Andra uppgifter — eventuella ytterligare/valfria regler kan tillämpas för att förbättra datakvaliteten.
Transformation anses allmänt vara den viktigaste delen av ETL-processen. Datatransformation förbättrar dataintegriteten – tar bort dubbletter och säkerställer att rådata anländer till sin nya destination helt kompatibel och redo att användas.
Steg 3: LOAD
Det sista steget i ETL-processen är att ladda nyomvandlade data till en ny destination (data lake eller data warehouse.) Data kan laddas på en gång (full load) eller med schemalagda intervall (incremental load).
Full laddning — I ett ETL-scenario med full laddning går allt som kommer från transformations steget in i nya, unika poster i data warehouse eller data repository. Även om det kan finnas tillfällen då detta är användbart för analysändamål, producerar fulladdningar datauppsättningar som växer exponentiellt och snabbt kan bli svåra att underhålla.
Inkrementell laddning — En mindre omfattande men mer hanterbar metod är inkrementell laddning. Inkrementell laddning jämför inkommande data med vad som redan finns till hands och producerar bara ytterligare poster om ny och unik information hittas. Denna metod tillåter mindre och billigare data warehouse att underhålla men är mer krävande att sätta upp som metod.
ELT — nästa generation av ETL
ELT är en modern version av den äldre processen att extrahera, transformera och ladda där transformationer äger rum innan data laddas. Med tiden har det visat sig att köra transformationer innan laddningsfasen resulterar i en mer komplex datareplikeringsprocess. Medan syftet med ETL är detsamma som ELT, har metoden utvecklats för bättre bearbetning.
ELT vs ETL
Traditionell ETL-programvara hjälper en att extrahera och transformera data från olika källor innan de laddas in i ett data warehouse eller data lake. Med introduktionen av moln data warehouse fanns det inte längre behov av datarensning på dedikerad ETL-maskin innan man laddade in i data i data warehouse eller data lake.
- EXTRAHERA - Extrahera data från flera datakällor och kopplingar
- LADDA - Ladda den i molnets data warehouse
- TRANSFORMERA - Förvandla den med kraften och skalbarheten hos molnplattformen.
Om man fortfarande har on-prem och data inte kommer från flera olika källor, passar ETL-verktyg fortfarande behovet. Men i takt med att fler företag går över till en molndataarkitektur (eller hybrid), är ELT-processer mer anpassningsbara och skalbara för att utveckla behoven hos molnbaserade företag.
Slutplädering
Att arbeta med data och dess flöden har alltid varit nödvändigt. Det ingår i det dagliga arbetet som arbetar med någon form av utveckling eller informationsbedömning (läs analys). Men med den mängd som hela tiden genereras, har en yrkesroll skjutit upp som en raket; dataingenjören. Tack vare ovan beskrivna processer och de verktyg som finns tillgängliga är det också ett yrke som är relativt lätt att sätta sig in i. Vissa verktyg har till och med trevliga gränssnitt med lådor och flödespilar. Koppla ihop dessa och tryck på play, le voilà! Många gånger skapar vi även skript som gör något vid sidan om eller kanske att det är så verktyget fungerar, att det kör våra skript på ett strukturerat sätt (exempelvis SQL i DBT, Data Build Tool, eller Python i Apache Airflow). Att skriva sina egna skript är att ta sina kunskaper till nästa nivå samt, vad viktigare är, lära känna sitt data. Att bli lite smutsig, rulla runt i dataträsket, knåda algoritmer, känna de små bitsen rinna mellan fingrarna. Det är så vi lär känna datan. Det är så vi kan bemästra den. Nå nästa nivå.
Level up!
Är du nyfiken på vad Kvadrat kan göra för dig och ditt företag? Läs mer här.